Un UUID, que significa «identificador único universal», no es otra cosa que un modo de diferenciar universalmente un elemento. Habitualmente, en MySQL se suelen usar identificadores representados por un número entero. Sin embargo, los UUID suelen ser cadenas más largas de números, texto o una combinación de ambos que evitan dar a conocer cosas como el orden lógico de los registros.
Mientras que el uso de un número entero es más práctico, en ocasiones, tenemos que almacenar miles e incluso millones de elementos que queremos referenciar universalmente mediante un UUID, ocasionando cierta pérdida de rendimiento cuando obtenemos los registros.
Contenidos
Cómo usar UUIDs
En MySQL, lo más habitual es almacenar los UUIDs en la base de datos como un campo CHAR(36). Tal y como podemos ver, almacenarlos de esta forma está ampliamente aceptado. Sin embargo, esto supone grandes problemas de rendimiento, ya que MySQL no será capaz de indexar correctamente los registros de las tablas.
Cómo optimizar UUIDs
Si optamos por almacenar los UUID en un campo de tipo BINARY obtendremos grandes mejoras de rendimiento, ya que MySQL indexará este campo con más facilidad. En concreto, las consultas a las tablas se realizarán de media 1.6 veces más rápido con grandes volúmenes de datos.
Además, lo habitual es que algunas partes de los UUID representen la fecha actual. Esto suele provocar que los índices UUID se almacenen en la base de datos de un modo no ordenado, por lo que su rendimiento será inferior al de los índices ordenados.
Los generadores de UUIDs suelen crear valores en base a la fecha actual. Debes asegurarte de que los bits que se corresponden con las fechas estén en el orden correcto. Es decir, primero deberán ir los bits que se corresponden con el año, luego los que se corresponden con el mes y luego los que se corresponden con los días.
En el caso de la hora actual, deberás seguir el mismo criterio. De este modo obtendrás un rendimiento muy similar al que tendrías utilizando los típicos ID con AUTO_ INCREMENT.
A continuación puedes ver una tabla en donde se compara el tiempo que se tarda en obtener 1.000 registros a la base de datos:
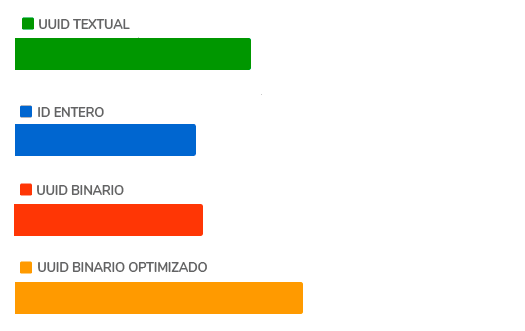 Tal y como puedes ver, la opción que mejor rinde de las que hemos visto consiste en usar un ID, y la peor consiste en usar un UUID optimizado. Esto echaría este artículo por tierra. Sin embargo, antes de sacar un veredicto, vamos a probar a obtener 500.000 registros de la base de datos:
Tal y como puedes ver, la opción que mejor rinde de las que hemos visto consiste en usar un ID, y la peor consiste en usar un UUID optimizado. Esto echaría este artículo por tierra. Sin embargo, antes de sacar un veredicto, vamos a probar a obtener 500.000 registros de la base de datos:
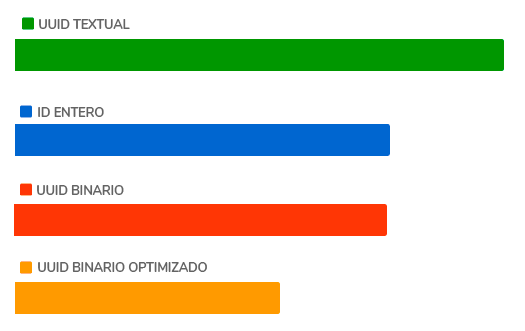
Tal y como puedes ver, por algún motivo, el UUID binario funciona incluso mejor que el típico ID entero que se usa por defecto, por lo que resulta ideal para obtener grandes cantidades de registros.
Cuándo utilizar UUIDs
En general, el uso de UUIDs siempre implicará complicaciones innecesarias, por lo que debes evitarlos salvo que los requieras específicamente por algún motivo. Por ejemplo, suelen usarse para evitar exponer las referencias a los registros almacenados en la base de datos, o también para ocultar el número de registros existente.
Dependiendo del lenguaje de programación que utilices, a continuación puedes encontrar algunas de las mejores librerías de generación y gestión de UUIDs:
- PHP: https://github.com/ramsey/uuid
- Java: https://docs.oracle.com/javase/6/docs/api/java/util/UUID.html
- Python: https://docs.python.org/3/library/uuid.html
Alternativas al uso de UUIDs
No siempre necesitas almacenar los UUIDs en la base de datos. Recientemente trabajé en una API en la que debíamos manejar tablas con casi un millón de registros. Uno de los requisitos era el uso de UUIDs, tanto por seguridad como por privacidad, con lo cual se barajaron diversas opciones.
Finalmente, la solución consistió en no almacenar los UUIDs en la base de datos y realizar una conversión de los identificadores de cada tabla de modo que no estuviesen expuestos al exterior:
- Llamada a la API desde el cliente.
- Traducción de los UUIDs que se reciben en el servidor a sus respectivos IDs.
- Obtención de los registros correspondientes de la base de datos MySQL mediante su ID.
- Cálculo del UUID de cada fila tomando como referencia el ID de cada una de ellas.
- Se genera la respuesta de la API desde el servidor, incluyendo el UUID de los registros en lugar de su ID.
En el caso de esta aplicación, rara vez teníamos que devolver muchos registros, por lo que la pérdida de rendimiento que conllevaba la obtención de los mismos con cada llamada a la API era más que asumible.
Siguiendo este método, debes asegurarte de que el UUID que se genera para cada ID sea siempre el mismo. Además, deberías usar un algoritmo que proporcione cierta seguridad a este método, de modo que no se pueda inferir desde el exterior cuál es el ID correspondiente a cada UUID, ya que de lo contrario el uso de UUIDs no tendría sentido.
Esto ha sido todo.
Edu Lázaro: Ingeniero técnico en informática, actualmente trabajo como desarrollador web y programador de videojuegos.

